|
4.3. Протокол IP
4.3. Протокол IP4.3.4. Маршрутизация без использования масокРассмотрим на примере IP-сети (рис. 4.14) алгоритм работы средств сетевого уровня по продвижению пакета в составной сети. При этом будем считать, что все узлы сети, рассматриваемой в примере, имеют адреса, основанные на классах, без использования масок. Особое внимание будет уделено взаимодействию протокола IP с протоколами разрешения адресов ARP и DNS.
Рис. 4.14. Пример взаимодействия компьютеров через сеть
4.3.5. Маршрутизация с использованием масокИспользование масок для структуризации сетиАлгоритм маршрутизации усложняется, когда в систему адресации узлов вносятся дополнительные элементы - маски. В чем же причина отказа от хорошо себя зарекомендовавшего в течение многих лет метода адресации, основанного на классах? Таких причин несколько, и одна из них - потребность в структуризации сетей. Часто администраторы сетей испытывают неудобства из-за того, что количество централизованно выделенных им номеров сетей недостаточно для того, чтобы структурировать сеть надлежащим образом, например разместить все слабо взаимодействующие компьютеры по разным сетям. В такой ситуации возможны два пути. Первый из них связан с получением от InterNIC или поставщика услуг Internet дополнительных номеров сетей. Второй способ, употребляющийся чаще, связан с использованием технологии масок, которая позволяет разделять одну сеть на несколько сетей. Допустим, администратор получил в свое распоряжение адрес класса В: 129.44.0.0. Он может организовать сеть с большим числом узлов, номера которых он может брать из диапазона 0.0.0.1-0.0.255.254 (с учетом того, что адреса из одних нулей и одних единиц имеют специальное назначение и не годятся для адресации узлов). Однако ему не нужна одна большая неструктурированная сеть, производственная необходимость диктует администратору другое решение, в соответствии с которым сеть должна быть разделена на три отдельных подсети, при этом трафик в каждой подсети должен быть надежно локализован. Это позволит легче диагностировать сеть и проводить в каждой из подсетей особую политику безопасности. Посмотрим, как решается эта проблема путем использования механизма масок. Итак, номер сети, который администратор получил от поставщика услуг, - 129.44.0.0 (10000001 00101100 00000000 00000000). В качестве маски было выбрано значение 255.255.192.0 (111111111111111111000000 00000000). После наложения маски на этот адрес число разрядов, интерпретируемых как номер сети, увеличилось с 16 (стандартная длина поля номера сети для класса В) до 18 (число единиц в маске), то есть администратор получил возможность использовать для нумерации подсетей два дополнительных бита. Это позволяет ему сделать из одного, централизованно заданного ему номера сети, четыре: 129.44.0.0 (10000001 00101100 00000000 00000000) 129.44.64.0 (10000001 00101100 01000000 00000000) 129.44.128.0 (10000001 00101100 10000000 00000000) 129.44.192.0 (10000001 00101100 11000000 00000000) Два дополнительных последних бита в номере сети часто интерпретируются как номера подсетей (subnet), и тогда четыре перечисленных выше подсети имеют номера 0 (00), 1 (01), 2 (10) и 3 (11) соответственно. ПРИМЕЧАНИЕ: Некоторые программные и аппаратные маршрутизаторы не поддерживают номера подсетей, которые состоят либо только из одних нулей, либо только из одних единиц. Например, для некоторых типов оборудования номер сети 129.44.0.0 с маской 255.255.192.0, использованный в нашем примере, окажется недопустимым, поскольку в этом случае разряды в поле номера подсети имеют значение 00. По аналогичным соображениям недопустимым может оказаться и номер сети 129.44.192.0 с тем же значением маски. Здесь номер подсети состоит только из единиц. Однако более современные маршрутизаторы свободны от этих ограничений. Поэтому, принимая решение об использовании механизма масок, необходимо выяснить характеристики того оборудования, которым вы располагаете, чтобы соответствующим образом сконфигурировать маршрутизаторы и компьютеры сети. В результате использования масок была предложена следующая схема распределения адресного пространства (рис. 4.15).
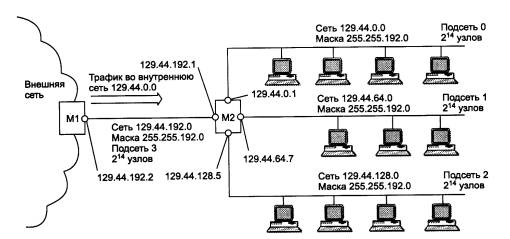
Рис. 4.15. Разделение адресного пространства сети класса В 129.44.0.0 на четыре равные части путем использования масок одинаковой длины 255.255.192.0 Сеть, получившаяся в результате проведенной структуризации, показана на рис. 4.16. Весь трафик во внутреннюю сеть 129.44.0.0, направляемый из внешней сети, поступает через маршрутизатор Ml. В целях структуризации информационных потоков во внутренней сети установлен дополнительный маршрутизатор М2.
Рис. 4.16. Маршрутизация с использованием масок одинаковой длины Все узлы были распределены по трем разным сетям, которым были присвоены номера 129.44.0.0, 129.44.64.0 и 129.44.128.0 и маски одинаковой длины - 255.255.192.0. Каждая из вновь образованных сетей была подключена к соответственно сконфигурированным портам внутреннего маршрутизатора М2. Кроме того, еще одна сеть (номер 129.44.192.0, маска 255.255.192.0) была выделена для создания соединения между внешним и внутренним маршрутизаторами. Особо отметим, что в этой сети для адресации узлов были заняты всего два адреса 129.44.192.1 (порт маршрутизатора М2) и 129.44.192.2 (порт маршрутизатора Ml), еще два адреса 129.44.192.0 и 129.44.192.255 являются особыми адресами. Следовательно, огромное число узлов (214 - 4) в этой подсети никак не используются. Извне сеть по-прежнему выглядит, как единая сеть класса В, а на местном уровне это полноценная составная сеть, в которую входят три отдельные сети. Приходящий общий трафик разделяется местным маршрутизатором М2 между этими сетями в соответствии с таблицей маршрутизации. (Заметим, что разделение большой сети, имеющей один адрес старшего класса, например А или В, с помощью масок несет в себе еще одно преимущество по сравнению с использованием нескольких адресов стандартных классов для сетей меньшего размера, например С. Оно позволяет скрыть внутреннюю структуру сети предприятия от внешнего наблюдения и тем повысить ее безопасность.) Рассмотрим, как изменяется работа модуля IP, когда становится необходимым учитывать наличие масок. Во-первых, в каждой записи таблицы маршрутизации появляется новое поле - поле маски. Во-вторых, меняется алгоритм определения маршрута по таблице маршрутизации. После того как IP-адрес извлекается из очередного полученного IP-пакета, необходимо определить адрес следующего маршрутизатора, на который надо передать пакет с этим адресом. Модуль IP последовательно просматривает все записи таблицы маршрутизации. С каждой записью производятся следующие действия.
Теперь рассмотрим этот алгоритм на примере маршрутизации пакетов в сети, изображенной на рис. 4.16. Все маршрутизаторы внешней сети, встретив пакеты с адресами, начинающимися с 129.44, интерпретируют их как адреса класса В и направляют по маршрутам, ведущим к маршрутизатору Ml. Маршрутизатор Ml в свою очередь направляет весь входной трафик сети 129.44.0.0 на маршрутизатор М2, а именно на его порт 129.44.192.1. Маршрутизатор М2 обрабатывает все поступившие на него пакеты в соответствии с таблицей маршрутизации (табл. 5.12). Таблица 4.12. Таблица маршрутизатора М2 в сети с масками одинаковой длины
Первые четыре записи в таблице соответствуют внутренним подсетям, непосредственно подключенным к портам маршрутизатора М2. Запись 0.0.0.0 с маской 0.0.0.0 соответствует маршруту по умолчанию. Действительно, любой адрес в пришедшем пакете после наложения на него маски 0.0.0.0 даст адрес сети 0.0.0.0, что совпадает с адресом, указанным в записи. Маршрутизатор выполняет сравнение с адресом 0.0.0.0 в последнюю очередь, в том случае когда пришедший адрес не дал совпадения ни с одной записью в таблице, отличающейся от 0.0.0.0. Записей с адресом 0.0.0.0 в таблице маршрутизации может быть несколько. В этом случае маршрутизатор передает пакет по всем таким маршрутам. Пусть, например, с маршрутизатора Ml на порт 129.44.192.1 маршрутизатора М2 поступает пакет с адресом назначения 129.44.78.200. Модуль IP начинает последовательно просматривать все строки таблицы, до тех пор пока не найдет совпадения номера сети в адресе назначения и в строке таблицы. Маска из первой строки 255.255.192.0 накладывается на адрес 129.44,78.200, в результате чего получается номер сети 129.44.64.0. В двоичном виде эта операция выглядит следующим образом: 10000001.00101100.01001110.11001000 11111111.11111111.11000000.00000000 - - - - - - - - - - - - - - - - - - - - - - - - - - - 10000001.00101100.01000000.00000000 Полученный номер 129.44.64.0 сравнивается с номером сети в первой строке таблицы 129.44.0.0. Поскольку они не совпадают, то происходит переход к следующей строке. Теперь извлекается маска из второй строки (в данном случае она имеет такое же значение, но в общем случае это совсем не обязательно) и накладывается на адрес назначения пакета 129.44.78.200. Понятно, что из-за совпадения длины масок будет получен тот же номер сети 129.44.64.0. Этот номер совпадает с номером сети во второй строке таблицы, а значит, найден маршрут для данного пакета - он должен быть отправлен на порт маршрутизатора 129.44.64.7 в сеть, непосредственно подключенную к данному маршрутизатору. Вот еще пример. IP-адрес 129.44.141.15(10000001 00101100 10001101 00001111), который при использовании классов делится на номер сети 129.44.0.0 и номер узла 0.0.141.15, теперь, при использовании маски 255.255.192.0, будет интерпретироваться как пара: 129.44.128.0 - номер сети, 0.0.13.15 - номер узла. Использование масок переменной длиныВ предыдущем примере использования масок (см. рис. 4.15 и 4.16) все подсети имеют одинаковую длину поля номера сети - 18 двоичных разрядов, и, следовательно, для нумерации узлов в каждой из них отводится по 14 разрядов. То есть все сети являются очень большими и имеют одинаковый размер. Однако в этом случае, как и во многих других, более эффективным явилось бы разбиение сети на подсети разного размера. В частности, большое число узлов, вполне желательное для пользовательской подсети, явно является избыточным для подсети, которая связывает два маршрутизатора по схеме «точка-точка». В этом случае требуются всего два адреса для адресации двух портов соседних маршрутизаторов. В предыдущем же примере для этой вспомогательной сети Ml - М2 был использован номер, позволяющий адресовать 214 узлов, что делает такое решение неприемлемо избыточным. Администратор может более рационально распределить имеющееся в его распоряжении адресное пространство с помощью масок переменной длины. На рис. 4.17 приведен пример распределения адресного пространства, при котором избыточность имеющегося множества IP-адресов может быть сведена к минимуму. Половина из имеющихся адресов (215) была отведена для создания сети с адресом 129.44.0.0 и маской 255.255.128.0. Следующая порция адресов, составляющая четверть всего адресного пространства (214), была назначена для сети 129.44.128.0 с маской 255.255.192.0. Далее в пространстве адресов был «вырезан» небольшой фрагмент для создания сети, предназначенной для связывания внутреннего маршрутизатора М2 с внешним маршрутизатором Ml.
Рис. 4.17. Разделение адресного пространства сети класса В 129.44.0.0 на сети разного размера путем использования масок переменной длины В IP-адресе такой вырожденной сети для поля номера узла как минимум должны быть отведены два двоичных разряда. Из четырех возможных комбинаций номеров узлов: 00, 01,10 и 11 два номера имеют специальное назначение и не могут быть присвоены узлам, но оставшиеся два 10 и 01 позволяет адресовать порты маршрутизаторов. В нашем примере сеть была выбрана с некоторым запасом - на 8 узлов. Поле номера узла в таком случае имеет 3 двоичных разряда, маска в десятичной нотации имеет вид 255.255.255.248, а номер сети, как видно из рис. 4.17, равен в данном конкретном случае 129.44.192.0. Если эта сеть является локальной, то на ней могут быть расположены четыре узла помимо двух портов маршуртизаторов. ПРИМЕЧАНИЕ: Заметим, что глобальным связям между маршрутизаторами типа «точка-точка» не обязательно давать IP-адреса, так как к такой сети не могут подключаться никакие другие узлы, кроме двух портов маршрутизаторов. Однако чаще всего такой вырожденной сети все же дают IP-адрес. Это делается, например, для того, чтобы скрыть внутреннюю структуру сети и обращаться к ней по одному адресу входного порта маршрутизатора, в данном примере по адресу 129.44.192.1. Кроме того, этот адрес может понадобиться при туннелировании немаршрутизируемых протоколов в IP-пакеты, что будет рассмотрено ниже. Оставшееся адресное пространство администратор может «нарезать» на разное количество сетей разного объема в зависимости от своих потребностей. Из оставшегося пула (214 - 4) адресов администратор может образовать еще одну достаточно большую сеть с числом узлов 213. При этом свободными останутся почти столько же адресов (213 - 4), которые также могут быть использованы для создания новых сетей. К примеру, из этого «остатка» можно образовать 31 сеть, каждая из которых равна размеру стандартной сети класса С, и к тому же еще несколько сетей меньшего размера. Ясно, что разбиение может быть другим, но в любом случае с помощью масок переменного размера администратор всегда имеет возможность гораздо рациональнее использовать все имеющиеся у него адреса. На рис. 4.18 показана схема сети, структурированной с помощью масок переменной длины.
Рис. 4.18. Сеть, структурированная с использованием масок переменной длины Таблица маршрутизации М2, соответствующая структуре сети, показанной на рис. 4.18, содержит записи о четырех непосредственно подключенных сетях и запись о маршрутизаторе по умолчанию (табл. 4.13). Процедура поиска маршрута при использовании масок переменной длины ничем не отличается от подобной процедуры, описанной ранее для масок одинаковой длины. Таблица 4.13. Таблица маршрутизатора М2 в сети с масками переменной длины
Некоторые особенности масок переменной длины проявляются при наличии так называемых «перекрытий». Под перекрытием понимается наличие нескольких маршрутов к одной и той же сети или одному и тому же узлу. В этом случае адрес сети в пришедшем пакете может совпасть с адресами сетей, содержащихся сразу в нескольких записях таблицы маршрутизации. Рассмотрим пример. Пусть пакет, поступивший из внешней сети на маршрутизатор Ml, имеет адрес назначения 129.44.192.5. Ниже приведен фрагмент таблицы маршрутизации маршрутизатора Ml. Первая из приведенных двух записей говорит о том, что все пакеты, адреса которых начинаются на 129.44, должны быть переданы на маршрутизатор М2. Эта запись выполняет агрегирование адресов всех подсетей, созданных на базе одной сети 129.44.0.0. Вторая строка говорит о том, что среди всех возможных подсетей сети 129.44.0.0 есть одна, 129.44.192.0, для которой пакеты можно направлять непосредственно, а не через маршрутизатор М2.
Если следовать стандартному алгоритму поиска маршрута по таблице, то сначала на адрес назначения 129.44.192.5 накладывается маска из первой строки 255.255.0.0 и получается результат 129.44.0.0, который совпадает с номером сети в этой строке. Но и при наложении на адрес 129.44.192.5 маски из второй строки 255.255.255.248 полученный результат 129.44.192.0 также совпадает с номером сети во второй строке. В таких случаях должно быть применено следующее правило: «Если адрес принадлежит нескольким подсетям в базе данных маршрутов, то продвигающий пакет маршрутизатор использует наиболее специфический маршрут, то есть выбирается адрес подсети, дающий большее совпадение разрядов». В данном примере будет выбран второй маршрут, то есть пакет будет передан в непосредственно подключенную сеть, а не пойдет кружным путем через маршрутизатор М2. Механизм выбора самого специфического маршрута является обобщением понятия «маршрут по умолчанию». Поскольку в традиционной записи для маршрута по умолчанию 0.0.0.0 маска 0.0.0.0 имеет нулевую длину, то этот маршрут считается самым неспецифическим и используется только при отсутствии совпадений со всеми остальными записями из таблицы маршрутизации. ПРИМЕЧАНИЕ: В IP-пакетах при использовании механизма масок по-прежнему передается только IP-адрес назначения, а маска сети назначения не передается. Поэтому из IP-адреса пришедшего пакета невозможно выяснить, какая часть адреса относится к номеру сети, а какая - к номеру узла. Если маски во всех подсетях имеют один размер, то это не создает проблем. Если же для образования подсетей применяют маски переменной длины, то маршрутизатор должен каким-то образом узнавать, каким адресам сетей какие маски соответствуют. Для этого используются протоколы маршрутизации, переносящие между маршрутизаторами не только служебную информацию об адресах сетей, но и о масках, соответствующих этим номерам. К таким протоколам относятся протоколы RIPv2 и OSPF, а вот, например, протокол RIP маски не распространяет и для использования масок переменной длины не подходит. Технология бесклассовой междоменной маршрутизации CIDRЗа последние несколько лет в сети Internet многое изменилось: резко возросло число узлов и сетей, повысилась интенсивность трафика, изменился характер передаваемых данных. Из-за несовершенства протоколов маршрутизации обмен сообщениями об обновлении таблиц стал иногда приводить к сбоям магистральных маршрутизаторов из-за перегрузки при обработке большого объема служебной информации. Так, в 1994 году таблицы магистральных маршрутизаторов в Internet содержали до 70 000 маршрутов. На решение этой проблемы была направлена, в частности, и технология бес-классовой междоменной маршрутизации (Classless Inter-Domain Routing, CIDR), впервые о которой было официально объявлено в 1993 году, когда были опубликованы RFC 1517, RFC 1518, RFC 1519 и RFC 1520. Суть технологии CIDR заключается в следующем. Каждому поставщику услуг Internet должен назначаться непрерывный диапазон в пространстве IP-адресов. При таком подходе адреса всех сетей каждого поставщика услуг имеют общую старшую часть - префикс, поэтому маршрутизация на магистралях Internet может осуществляться на основе префиксов, а не полных адресов сетей. Агрегирование адресов позволит уменьшить объем таблиц в маршрутизаторах всех уровней, а следовательно, ускорить работу маршрутизаторов и повысить пропускную способность Internet. Деление IP-адреса на номер сети и номер узла в технологии CIDR происходит не на основе нескольких старших бит, определяющих класс сети (А, В или С), а на основе маски переменной длины, назначаемой поставщиком услуг. На рис. 4.19 показан пример некоторого пространства IP-адресов, которое имеется в распоряжении гипотетического поставщика услуг. Все адреса имеют общую часть в k старших разрядах - префикс. Оставшиеся п разрядов используются для дополнения неизменяемого префикса переменной частью адреса. Диапазон имеющихся адресов в таком случае составляет 2n. Когда потребитель услуг обращается к поставщику услуг с просьбой о выделении ему некоторого количества адресов, то в имеющемся пуле адресов «вырезается» непрерывная область S1, S2, S3 или S4 соответствующего размера. Причем границы этой области выбираются такими, чтобы для нумерации требуемого числа узлов хватило некоторого числа младших разрядов, а значения всех оставшихся (старших) разрядов было одинаковым у всех адресов данного диапазона. Таким условиям могут удовлетворять только области, размер которых кратен степени двойки, А границы выделяемого участка должны быть кратны требуемому размеру.
Рис. 4.19. Технологии CIDR Рассмотрим пример. Пусть поставщик услуг Internet располагает пулом адресов в диапазоне 193.20.0.0-193.23.255.255 (1100 0001.0001 0100.0000 0000.0000 0000-11000001.0001 0111.11111111.11111111) с общим префиксом 193.20(11000001.0001 01) и маской, соответствующей этому префиксу 255.252.0.0. Если абоненту этого поставщика услуг требуется совсем немного адресов, например 13, то поставщик мог бы предложить ему различные варианты: сеть 193.20.30.0, сеть 193.20.30.16 или сеть 193.21.204.48, все с одним и тем же значением маски 255.255.255.240. Во всех случаях в распоряжении абонента для нумерации узлов имеются 4 младших бита. Рассмотрим другой вариант, когда к поставщику услуг обратился крупный заказчик, сам, возможно собирающийся оказывать услуги по доступу в Internet. Ему требуется блок адресов в 4000 узлов. В этом случае поставщик услуг мог бы предложить ему, например, диапазон адресов 193,22.160.0-193.22.175.255 с маской 255.255.240.0. Агрегированный номер сети (префикс) в этом случае будет равен 193.22.160.0. Администратор маршрутизатора М2 (рис. 4.20) поместит в таблицу маршрутизации только по одной записи на каждого клиента, которому был выделен пул адресов, независимо от количества подсетей, организованных клиентом. Если клиент, получивший сеть 193.22.160.0, через некоторое время разделит ее адресное пространство в 4096 адресов на 8 подсетей, то в маршрутизаторе М2 первоначальная информация о выделенной ему сети не изменится.
Рис. 4.20. Выигрыш в количестве записей в маршрутизаторе при использовании технологии CIDR Для поставщика услуг верхнего уровня, поддерживающего клиентов через маршрутизатор Ml, усилия поставщика услуг нижнего уровня по разделению его адресного пространства также не будут заметны. Запись 193.20.0,0 с маской 255.252.0,0 полностью описывает сети поставщика услуг нижнего уровня в маршрутизаторе Ml. Итак, внедрение технологии CIDR позволяет решить две основные задачи.
Если все поставщики услуг Internet будут придерживаться стратегии CIDR, то особенно заметный выигрыш будет достигаться в магистральных маршрутизаторах. Технология CIDR уже успешно используется в текущей версии IPv4 и поддерживается такими протоколами маршрутизации, как OSPF, RIP-2, BGP4. Предполагается, что эти же протоколы будут работать и с новой версией протокола IPv6. Следует отметить, что в настоящее время технология CIDR поддерживается магистральными маршрутизаторами Internet, а не обычными хостами в локальных сетях. Использование CIDR в сетях IPv4 в общем случае требует перенумерации сетей. Поскольку эта процедура сопряжена с определенными временными и материальными затратами, для ее проведения пользователей нужно каким-либо образом стимулировать. В качестве таких стимулов рассматривается, например, введение оплаты за строку в таблице маршрутизации или же за количество узлов в сети. При использовании классов сетей абонент часто не полностью занимает весь допустимый диапазон адресов узлов - 254 адреса для сети класса С или 65 534 адреса для сети класса В. Часть адресов узлов обычно пропадает. Требование оплаты каждого адреса узла поможет пользователю решиться на перенумерацию, с тем чтобы получить ровно столько адресов, сколько ему нужно. 4.3.6. Фрагментация IP-пакетовПротокол IP позволяет выполнять фрагментацию пакетов, поступающих на входные порты маршрутизаторов. Следует различать фрагментацию сообщений в узле-отправителе и динамическую фрагментацию сообщений в транзитных узлах сети - маршрутизаторах. Практически во всех стеках протоколов есть протоколы, которые отвечают за фрагментацию сообщений прикладного уровня на такие части, которые укладываются в кадры канального уровня. В стеке TCP/IP эту задачу решает протокол TCP, который разбивает поток байтов, передаваемый ему с прикладного уровня на сообщения нужного размера (например, на 1460 байт для протокола Ethernet). Поэтому протокол IP в узле-отправителе не использует свои возможности по фрагментации пакетов. А вот при необходимости передать пакет в следующую сеть, для которой размер пакета является слишком большим, IP-фрагментация становится необходимой. В функции уровня IP входит разбиение слишком длинного для конкретного типа составляющей сети сообщения на более короткие пакеты с созданием соответствующих служебных полей, нужных для последующей сборки фрагментов в исходное сообщение. В большинстве типов локальных и глобальных сетей значения MTU, то есть максимальный размер поля данных, в которое должен инкапсулировать свой пакет протокол IP, значительно отличается. Сети Ethernet имеют значение MTU, равное 1500 байт, сети FDDI - 4096 байт, а сети Х.25 чаще всего работают с MTU в 128 байт. IP-пакет может быть помечен как не фрагментируемый. Любой пакет, помеченный таким образом, не может быть фрагментирован модулем IP ни при каких условиях. Если же пакет, помеченный как не фрагментируемый, не может достигнуть получателя без фрагментации, то этот пакет просто уничтожается, а узлу-отправителю посылается соответствующее ICMP-сообщение. Протокол IP допускает возможность использования в пределах отдельной подсети ее собственных средств фрагментирования, невидимых для протокола IP. Например, технология АТМ делит поступающие IP-пакеты на ячейки с полем данных в 48 байт с помощью своего уровня сегментирования, а затем собирает ячейки в исходные пакеты на выходе из сети. Но такие технологии, как АТМ, являются скорее исключением, чем правилом. Процедуры фрагментации и сборки протокола IP рассчитаны на то, чтобы пакет мог быть разбит на практически любое количество частей, которые впоследствии могли бы быть вновь собраны. Получатель фрагмента использует поле идентификации для того, чтобы не перепутать фрагменты различных пакетов. Модуль IP, отправляющий пакет, устанавливает в поле идентификации значение, которое должно быть уникальным для данной пары отправитель - получатель, а также время, в течение которого пакет может быть активным в сети. Поле смещения фрагмента сообщает получателю положение фрагмента в исходном пакете. Смещение фрагмента и длина определяют часть исходного пакета, принесенную этим фрагментом. Флаг «more fragments» показывает появление последнего фрагмента. Модуль протокола IP, отправляющий неразбитый на фрагменты пакет, устанавливает в нуль флаг «more fragments» и смещение во фрагменте. Эти поля дают достаточное количество информации для сборки пакета. Чтобы разделить на фрагменты большой пакет, модуль протокола IP, установленный, например, на маршрутизаторе, создает несколько новых пакетов и копирует содержимое полей IP-заголовка из большого пакета в IP-заголовки всех новых пакетов. Данные из старого пакета делятся на соответствующее число частей, размер каждой из которых, кроме самой последней, обязательно должен быть кратным 8 байт. Размер последней части данных равен полученному остатку. Каждая из полученных частей данных помещается в новый пакет. Когда происходит фрагментация, то некоторые параметры IP-заголовка копируются в заголовки всех фрагментов, а другие остаются лишь в заголовке первого фрагмента. Процесс фрагментации может изменить значения данных, расположенных в поле параметров, и значение контрольной суммы заголовка, изменить значение флага «more fragments» и смещение фрагмента, изменить длину IP-заголовка и общую длину пакета, В заголовок каждого пакета заносятся соответствующие значения в поле смещения «fragment offset», а в поле общей длины пакета помещается длина каждого пакета. Первый фрагмент будет иметь в поле «fragment offset» нулевое значение. Во всех пакетах, кроме последнего, флаг «more fragments» устанавливается в единицу, а в последнем фрагменте - в нуль. Чтобы собрать фрагменты пакета, модуль протокола IP (например, модуль на хост - компьютере) объединяет IP-пакеты, имеющие одинаковые значения в полях идентификатора, отправителя, получателя и протокола. Таким образом, отправитель должен выбрать идентификатор таким образом, чтобы он был уникален для данной пары отправитель-получатель, для данного протокола и в течение того времени, пока данный пакет (или любой его фрагмент) может существовать в составной IP-сети. Очевидно, что модуль протокола IP, отправляющий пакеты, должен иметь таблицу идентификаторов, где каждая запись соотносится с каждым отдельным получателем, с которым осуществлялась связь, и указывает последнее значение максимального времени жизни пакета в IP-сети. Однако, поскольку поле идентификатора допускает 65 536 различных значений, некоторые хосты могут использовать просто уникальные идентификаторы, не зависящие от адреса получателя. В некоторых случаях целесообразно, чтобы идентификаторы IP-пакетов выбирались протоколами более высокого, чем IP, уровня. Например, в протоколе TCP предусмотрена повторная передача ТСР - сегментов, по каким-либо причинам не дошедшим до адресата. Вероятность правильного приема увеличивалась бы, если бы при повторной передаче идентификатор для IP-пакета был бы тем же, что и в исходном IP-пакете, поскольку его фрагменты могли бы использоваться для сборки правильного ТСР - сегмента. Процедура объединения заключается в помещении данных из каждого фрагмента в позицию, указанную в заголовке пакета в поле «fragment offset». Каждый модуль IP должен быть способен передать пакет из 68 байт без дальнейшей фрагментации. Это связано с тем, что IP-заголовок может включать до 60 байт, а минимальный фрагмент данных - 8 байт. Каждый получатель должен быть в состоянии принять пакет из 576 байт в качестве единого куска либо в виде фрагментов, подлежащих сборке. Если бит флага запрета фрагментации (Don't Fragment, DF) установлен, то фрагментация данного пакета запрещена, даже если в этом случае он будет потерян. Данное средство может использоваться для предотвращения фрагментации в тех случаях, когда хост - получатель не имеет достаточных ресурсов для сборки фрагментов. Работа протокола IP по фрагментации пакетов в хостах и маршрутизаторах иллюстрируется на рис. 4.21.
Рис.4.21. Фрагментация IP-пакетов при передаче между сетями с разным максимальным размером пакетов: К1 и 01 - канальный и физический уровень сети 1; К2 и Ф2 - канальный и физический уровень сети 2 Пусть компьютер 1 связан с сетью, имеющей значение MTU в 4096 байт, например с сетью FDDI, При поступлении на IP-уровень компьютера 1 сообщения от транспортного уровня размером в 5600 байт протокол IP делит его на два IP-пакета, устанавливая в первом пакете признак фрагментации и присваивая пакету уникальный идентификатор, например 486, В первом пакете величина поля смещения равна 0, а во втором - 2800. Признак фрагментации во втором пакете равен нулю, что показывает, что это последний фрагмент пакета. Общая величина IP-пакета составляет 2800 плюс 20 (размер IP-заголовка), то есть 2820 байт, что умещается в поле данных кадра FDDI. Далее модуль IP компьютера 1 передает эти пакеты своему сетевому интерфейсу (образуемому протоколами канального уровня К 1 и физического уровня Ф1), Сетевой интерфейс отправляет кадры следующему маршрутизатору. После того, как кадры пройдут уровень сетевого интерфейса маршрутизатора (К1 и Ф1) и освободятся от заголовков FDDI, модуль IP по сетевому адресу определяет, что прибывшие два пакета нужно передать в сеть 2, которая является сетью Ethernet и имеет значение MTU, равное 1500. Следовательно, прибывшие IP-пакеты необходимо фрагментировать. Маршрутизатор извлекает поле данных из каждого пакета и делит его еще пополам, чтобы каждая часть уместилась в поле данных кадра Ethernet. Затем он формирует новые IP-пакеты, каждый из которых имеет длину 1400 + 20 - 1420 байт, что меньше 1500 байт, поэтому они нормально помещаются в поле данных кадров Ethernet. В результате в компьютер 2 по сети Ethernet приходят четыре IP-пакета с общим идентификатором 486, что позволяет протоколу IP, работающему в компьютере 2, правильно собрать исходное сообщение. Если пакеты пришли не в том порядке, в котором были посланы, то смещение укажет правильный порядок их объединения. Отметим, что IP-маршрутизаторы не собирают фрагменты пакетов в более крупные пакеты, даже если на пути встречается сеть, допускающая такое укрупнение. Это связано с тем, что отдельные фрагменты сообщения могут перемещаться по интерсети по различным маршрутам, поэтому нет гарантии, что все фрагменты проходят через какой-либо промежуточный маршрутизатор на их пути. При приходе первого фрагмента пакета узел назначения запускает таймер, который определяет максимально допустимое время ожидания прихода остальных фрагментов этого пакета. Таймер устанавливается на максимальное из двух значений: первоначальное установочное время ожидания и время жизни, указанное в принятом фрагменте. Таким образом, первоначальная установка таймера является нижней границей для времени ожидания при c6opi. Если таймер истекает раньше прибытия последнего фрагмента, то все ресурсы сборки, связанные с данным пакетом, освобождаются, все полученные к этому моменту фрагменты пакета отбрасываются, а в узел, пославший исходный пакет, направляется сообщение об ошибке с помощью протокола ICMP. 4.3.7. Протокол надежной доставки TCP-сообщенийПротокол IP является дейтаграммным протоколом и поэтому по своей природе не может гарантировать надежность передачи данных. Эту задачу - обеспечение надежного канала обмена данными между прикладными процессами в составной сети -решает протокол TCP (Transmission Control Protocol), относящийся к транспортному уровню. Протокол TCP работает непосредственно над протоколом IP и использует для транспортировки своих блоков данных потенциально ненадежный протокол IP. Надежность передачи данных протоколом TCP достигается за счет того, что он основан на установлении логических соединений между взаимодействующими процессами. До тех пор пока программы протокола TCP продолжают функционировать корректно, а составная сеть не распалась на несвязные части, ошибки в передаче данных на уровне протокола IP не будут влиять на правильное получение данных. Протокол IP используется протоколом TCP в качестве транспортного средства. Перед отправкой своих блоков данных протокол TCP помещает их в оболочку IP-пакета. При необходимости протокол IP осуществляет любую фрагментацию и сборку блоков данных TCP, требующуюся для осуществления передачи и доставки через множество сетей и промежуточных шлюзов. На рис. 4.22 показано, как процессы, выполняющиеся на двух конечных узлах, устанавливают с помощью протокола TCP надежную связь через составную сеть, все узлы которой используют для передачи сообщений дейтаграммный протокол IP.
Рис. 4.22. TCP-соединение создает надежный канал связи между конечными узлами ПортыПротокол TCP взаимодействует через межуровневые интерфейсы с ниже лежащим протоколом IP и с выше лежащими протоколами прикладного уровня или приложениями. В то время как задачей сетевого уровня, к которому относится протокол IP, является передача данных между произвольными узлами сети, задача транспортного уровня, которую решает протокол TCP, заключается в передаче данных между любыми прикладными процессами, выполняющимися на любых узлах сети. Действительно, после того как пакет средствами протокола IP доставлен в компьютер-получатель, данные необходимо направить конкретному процессу-получателю. Каждый компьютер может выполнять несколько процессов, более того, прикладной процесс тоже может иметь несколько точек входа, выступающих в качестве адреса назначения для пакетов данных. Пакеты, поступающие на транспортный уровень, организуются операционной системой в виде множества очередей к точкам входа различных прикладных процессов. В терминологии TCP/IP такие системные очереди называются портами. Таким образом, адресом назначения, который используется протоколом TCP, является идентификатор (номер) порта прикладной службы. Номер порта в совокупности с номером сети и номером конечного узла однозначно определяют прикладной процесс в сети. Этот набор идентифицирующих параметров имеет название сокет (socket). Назначение номеров портов прикладным процессам осуществляется либо централизованно, если эти процессы представляют собой популярные общедоступные службы (например, номер 21 закреплен за службой удаленного доступа к файлам FTP, a 23 - за службой удаленного управления telnet), либо локально для тех служб, которые еще не стали столь распространенными, чтобы закреплять за ними стандартные (зарезервированные) номера. Централизованное присвоение службам номеров портов выполняется организацией Internet Assigned Numbers Authority (IANA). Эти номера затем закрепляются и опубликовываются в стандартах Internet (RFC 1700). Локальное присвоение номера порта заключается в том, что разработчик некоторого приложения просто связывает с ним любой доступный, произвольно выбранный числовой идентификатор, обращая внимание на то, чтобы он не входил в число зарезервированных номеров портов. В дальнейшем все удаленные запросы к данному приложению от других приложений должны адресоваться с указанием назначенного ему номера порта. Протокол TCP ведет для каждого порта две очереди: очередь пакетов, поступающих в данный порт из сети, и очередь пакетов, отправляемых данным портом в сеть. Процедура обслуживания протоколом TCP запросов, поступающих от нескольких различных прикладных служб, называется мультиплексированием. Обратная процедура распределения протоколом TCP поступающих от сетевого уровня пакетов между набором высокоуровневых служб, идентифицированных номерами портов, называется демультиплексированием (рис. 4.23).
Рис. 4.23. Функции протокола TCP no мультиплексированию и демультиплексированию потоков Сегменты и потокиЕдиницей данных протокола TCP является сегмент. Информация, поступающая к протоколу TCP в рамках логического соединения от протоколов более высокого уровня, рассматривается протоколом TCP как неструктурированный поток байтов. Поступающие данные буферизуются средствами TCP. Для передачи на сетевой уровень из буфера «вырезается» некоторая непрерывная часть данных, которая и называется сегментом (см. рис. 4.23). В отличие от многих других протоколов, протокол TCP подтверждает получение не пакетов, а байтов потока. Не все сегменты, посланные через соединение, будут одного и того же размера, однако оба участника соединения должны договориться о максимальном размере сегмента, который они будут использовать. Этот размер выбирается таким образом, чтобы при упаковке сегмента в IP-пакет он помещался туда целиком, то есть максимальный размер сегмента не должен превосходить максимального размера поля данных IP-пакета, В противном случае пришлось бы выполнять фрагментацию, то есть делить сегмент на несколько частей, чтобы разместить его в IP-пакете, СоединенияДля организации надежной передачи данных предусматривается установление логического соединения между двумя прикладными процессами. Поскольку соединения устанавливаются через ненадежную коммуникационную систему, основанную на протоколе IP, то во избежание ошибочной инициализации соединений используется специальная многошаговая процедура подтверждения связи. Соединение в протоколе TCP идентифицируется парой полных адресов обоих взаимодействующих процессов - сокетов. Каждый из взаимодействующих процессов может участвовать в нескольких соединениях. Формально соединение можно определить как набор параметров, характеризующий процедуру обмена данными между двумя процессами. Помимо полных адресов процессов этот набор включает и параметры, значения которых определяются в результате переговорного процесса модулей TCP двух сторон соединения. К таким параметрам относятся, в частности, согласованные размеры сегментов, которые может посылать каждая из сторон, объемы данных, которые разрешено передавать без получения на них подтверждения, начальные и текущие номера передаваемых байтов. Некоторые из этих параметров остаются постоянными в течение всего сеанса связи, а некоторые адаптивно изменяются. В рамках соединения осуществляется обязательное подтверждение правильности приема для всех переданных сообщений и при необходимости выполняется повторная передача. Соединение в TCP позволяет вести передачу данных одновременно в обе Стороны, то есть полнодуплексную передачу. Реализация скользящего окна в протоколе TCPВ рамках установленного соединения правильность передачи каждого сегмента должна подтверждаться квитанцией получателя. Квитирование - это один из традиционных методов обеспечения надежной связи. В протоколе TCP используется частный случай квитирования - алгоритм скользящего окна. Идея этого алгоритма была изложена в главе 2, «Основы передачи дискретных данных». Особенность использования алгоритма скользящего окна в протоколе TCP состоит в том, что, хотя единицей передаваемых данных является сегмент, окно определено на множестве нумерованных байтов неструктурированного потока данных, поступающих с верхнего уровня и буферизуемых протоколом TCP. Получающий модуль TCP отправляет «окно» посылающему модулю TCP. Данное окно задает количество байтов (начиная с номера байта, о котором уже была выслана квитанция), которое принимающий модуль TCP готов в настоящий момент принять. Квитанция (подтверждение) посылается только в случае правильного приема данных, отрицательные квитанции не посылаются. Таким образом, отсутствие квитанции означает либо прием искаженного сегмента, либо потерю сегмента, либо потерю квитанции. В качестве квитанции получатель сегмента отсылает ответное сообщение (сегмент), в которое помещает число, на единицу превышающее максимальный номер байта в полученном сегменте. Это число часто называют номером очереди. На рис. 4.24 показан поток байтов, поступающий на вход протокола TCP. Из потока байтов модуль TCP нарезает последовательность сегментов. Для определенности на рисунке принято направление перемещения данных справа налево. В этом потоке можно указать несколько логических границ. Первая граница отделяет сегменты, которые уже были отправлены и на которые уже пришли квитанции. Следующую часть потока составляют сегменты, которые также уже отправлены, так как входят в границы, определенные окном, но квитанции на них пока не получены. Третья часть потока - это сегменты, которые пока не отправлены, но могут быть отправлены, так как входят в пределы окна. И наконец, последняя граница указывает на начало последовательности сегментов, ни один из которых не может быть отправлен до тех пор, пока не придет очередная квитанция и окно не будет сдвинуто вправо.
Рис. 4.24. Особенности реализации алгоритма скользящего окна в протоколе TCP Если размер окна равен W, а последняя по времени квитанция содержала значение N, то отправитель может посылать новые сегменты до тех пор, пока в очередной сегмент не попадет байт с номером N+W. Этот сегмент выходит за рамки окна, и передачу в таком случае необходимо приостановить до прихода следующей квитанции. Надежность передачи достигается благодаря подтверждениям и номерам очереди. Концептуально каждому байту данных присваивается номер очереди. Номер очереди для первого байта данных в сегменте передается вместе с этим сегментом и называется номером очереди для сегмента. Сегменты также несут номер подтверждения, который является номером для следующего ожидаемого байта данных, передаваемого в обратном направлении. Когда протокол TCP передает сегмент с данными, он помещает его копию в очередь повторной передачи и запускает таймер. Когда приходит подтверждение для этих данных, соответствующий сегмент удаляется из очереди. Если подтверждение не приходит до истечения срока, то сегмент посылается повторно. Выбор времени ожидания (тайм-аута) очередной квитанции является важной задачей, результат решения которой влияет на производительность протокола TCP. Тайм-аут не должен быть слишком коротким, чтобы по возможности исключить избыточные повторные передачи, которые снижают полезную пропускную способность системы. Но он не должен быть и слишком большим, чтобы избежать длительных простоев, связанных с ожиданием несуществующей или «заблудившейся» квитанции. При выборе величины тайм-аута должны учитываться скорость и надежность физических линий связи, их протяженность и многие другие подобные факторы. В протоколе TCP тайм-аут определяется с помощью достаточно сложного адаптивного алгоритма, идея которого состоит в следующем. При каждой передаче засекается время от момента отправки сегмента до прихода квитанции о его приеме (время оборота). Получаемые значения времени оборота усредняются с весовыми коэффициентами, возрастающими от предыдущего замера к последующему. Это делается с тем, чтобы усилить влияние последних замеров. В качестве тайм-аута выбирается среднее время оборота, умноженное на некоторый коэффициент. Практика показывает, что значение этого коэффициента должно превышать 2. В сетях с большим разбросом времени оборота при выборе тайм-аута учитывается и дисперсия этой величины. Поскольку каждый байт пронумерован, то каждый из них может быть опознан. Приемлемый механизм опознавания является накопительным, поэтому опознавание номера Х означает, что все байты с предыдущими номерами уже получены. Этот механизм позволяет регистрировать появление дубликатов в условиях повторной передачи. Нумерация байтов в пределах сегмента осуществляется так, чтобы первый байт данных сразу вслед за заголовком имел наименьший номер, а следующие за ним байты имели номера по возрастающей. Окно, посылаемое с каждым сегментом, определяет диапазон номеров очереди, которые отправитель окна (он же получатель данных) готов принять в настоящее время. Предполагается, что такой механизм связан с наличием в данный момент места в буфере данных. Варьируя величину окна, можно влиять на загрузку сети. Чем больше окно, тем большую порцию неподтвержденных данных можно послать в сеть. Но если пришло большее количество данных, чем может быть принято программой TCP, данные будут отброшены. Это приведет к излишним пересылкам информации и ненужному увеличению нагрузки на сеть и программу TCP. С другой стороны, указание окна малого размера может ограничить передачу данных скоростью, которая определяется временем путешествия по сети каждого посылаемого сегмента. Чтобы избежать применения малых окон, получателю данных предлагается откладывать изменение окна до тех пор, пока свободное место не составит 20-40 % от максимально возможного объема памяти для этого соединения. Но и отправителю не стоит спешить с посылкой данных, пока окно не станет достаточно большим. Учитывая эти соображения, разработчики протокола TCP предложили схему, согласно которой при установлении соединения заявляется большое окно, но впоследствии его размер существенно уменьшается. Если сеть не справляется с нагрузкой, то возникают очереди в промежуточных узлах - маршрутизаторах и в конечных узлах-компьютерах. При переполнении приемного буфера конечного узла «перегруженный» протокол TCP, отправляя квитанцию, помещает в нее новый, уменьшенный размер окна. Если он совсем отказывается от приема, то в квитанции указывается окно нулевого размера. Однако даже после этого приложение может послать сообщение на отказавшийся от приема порт. Для этого сообщение должно сопровождаться пометкой «срочно». В такой ситуации порт обязан принять сегмент, даже если для этого придется вытеснить из буфера уже находящиеся там данные. После приема квитанции с нулевым значением окна протокол-отправитель время от времени делает контрольные попытки продолжить обмен данными. Если протокол-приемник уже готов принимать информацию, то в ответ на контрольный 'запрос он посылает квитанцию с указанием ненулевого размера окна. Другим проявлением перегрузки сети является переполнение буферов в маршрутизаторах. В таких случаях они могут централизованно изменить размер окна, посылая управляющие сообщения некоторым конечным узлам, что позволяет им дифференцированно управлять интенсивностью потока данных в разных частях сети. Выводы
При использовании материалов сайта ссылка на проект http://www.compnets.narod.ru обязательна. All rights reserved. ©2006 compnets@yandex.ru - пишите письма |



















| Содержание | Тестирование | Рекомендации преподавателей | О проекте | Задай вопрос | Вперёд | Назад |